ML/MLOps
기반 다지기 - CPU, GPU, CUDA 편
minturtle
2024. 12. 20. 21:28
반응형
CPU vs GPU
- CPU와 GPU의 관계는 흔히 수학 교수 1명과 초등학생 100명으로 구분되고는 합니다.
- 그럼 CPU와 GPU가 정확히 뭔지, GPU Memory는 무엇인지 알아보는 시간을 가져보도록 하겠습니다.
- 또 이에 이어서 GPU를 사용할 때 빠질 수 없는 CUDA 라이브러리가 어떤 역할을 하는지 알아보도록 하겠습니다.
CPU와 GPU의 유사한 점
- CPU와 그래픽 처리 장치(GPU)는 모두 컴퓨터를 작동시키는 HW로, Processor라고 불립니다. 둘다 유사한 구조(ALU, Control Unit, Register, Cache)등의 유사한 구조를 가지고 있습니다.
- 각 Core 당 처리할 수 있는 명령어 단위를 HW Level Thread라고 하며, HyperThreading와 같은 Simultaneous Multi-Threading 기술이 적용되지 않았을 때 각 코어는 하나의 Thread를 할당 받아 실행합니다.(이 때 운영체제의 스케줄러가 HW thread에 Kernal Thread를 매핑 시켜 실제로 실행시킵니다.)
- 클록은 Processor 의 동작 주기를 의미하며, 클록 속도가 높을수록 CPU가 초당 처리하는 명령어의 수가 증가합니다.
- Processor는 자신이 처리할 수 있는 명령어의 모음을 갖고 있으며, 이를 명령어 세트라고 합니다.
CPU
- CPU는 OS를 포함한 모든 프로그램을 실행하는 데 필요한 모든 작업을 처리하는 역할을 합니다.
- Core는 제어 장치(Control Unit-Cu), ALU, 레지스터, 캐시 메모리로 구성되며, 이러한 Core가 여러개 있는 CPU를 Multi-Core CPU라고 부릅니다.
- 제어장치는 레지스터로부터 데이터를 읽어 들여 ALU가 연산을 수행하고, 그 결과값을 제어 장치를 사용해 외부 Device Driver로 전송하거나 메모리로 저장하도록 합니다.
- 캐시 메모리는 L1~L3까지 구성되어 있으며, 제어 장치가 메모리로 부터 데이터를 읽기전에 먼저 접근해 데이터를 가져오기 시도하는 고속 메모리입니다. 속도가 가장 빠른 L1부터 접근해 L3까지 캐시미스가 나면 메모리로 접근합니다.
- 보통 Multi-Core CPU에서 L1는 코어마다, L2는 코어마다 또는 일부 코어간, L3는 모든 코어가 공유하게 됩니다.
- 설계상 구조가 GPU보다 복잡하여 범용적이고 광범위한 명령어 세트를 처리할 수 있습니다.
GPU
- GPU는 CPU보다 성능은 떨어지지만 Core의 수를 CPU보다 훨씬 많이 사용해 간단한 병렬 작업에 특화되었습니다. 그럼 GPU의 Core가 CPU보다 성능이 떨어진다는 것이 무엇을 의미할까요?
- GPU Core는 일반적으로 CPU보다 클록 속도가 낮아 명령어 처리 속도가 느립니다.
- CPU Core보다 단순한 구조를 사용하여, 벡터 연산과 같은 병렬 연산에 최적화 된 명령어 세트를 보유하고 있습니다.
- 이러한 이유로 인해 GPU는 순차적으로 데이터를 처리하는 것 보다 같은 연산을 병렬적으로 동시에 처리하는 데 유리합니다.
- 다만 GPU는 앞서 언급하듯이 명령어 세트가 모자라기 때문에 실행은 여전히 CPU에 의해 수행되며, GPU는 CPU의 병렬 처리 도우미 정도로 생각하면 좋을 것 같습니다.
CPU Memory VS GPU Memory
- CPU Memory는 레지스터, Cache, RAM을 말하며, 일반적인 프로세스를 적재하고 CPU가 명령어를 처리할 때 사용됩니다.
- CPU와 Memory는 소켓 방식으로, 자유롭게 CPU나 RAM을 교체할 수 있습니다.
- GPU Memory(VRAM)는 CPU와 독립적으로 사용되는 GPU 전용 메모리 공간으로 GPU가 사용하는 일시적인 데이터 버퍼를 저장하기 위해 사용되는 메모리입니다.
- VRAM은 소켓 방식이 아닌 GPU와 VRAM이 직접적으로 납땜되는 식으로 동작해 GPU와 Memory를 분리하여 교체할 수 없습니다.
- 이 방식을 사용한 이유는 GPU는 많은 양의 데이터를 넓은 메모리 버스폭으로 동시에 전송되어야 하고, 물리적으로 최대한 가깝게 설계해야 하기 때문이라고 합니다.
SIMD와 SIMT
- GPU는 병렬적으로 많은 데이터에 대해 동일한 명령어를 적용할 때 가장 효율이잘 나오는데,
- GPU 실행 모델에는 SIMD(Single Instructure, Multi Data)와 SIMT(Single Instruction, Multi Thread)가 있으며,각각의 개념은 아래와 같습니다.
- SIMD : 하나의 명령어로 여러 데이터를 동시에 처리하는 병렬 처리 기법
- Single thread에서 벡터 연산을 수행하게 되며, 각 Thread를 Core에 1-1로 매핑시켜줘야 하기 때문에 이러한 매핑 과정이 번거롭습니다.
- SIMT : NVIDIA GPU에서 사용되는 병렬 처리 모델로, SIMD를 확장한 개념
- 각 Thread는 warp라는 단위로 묶이게 되며, 이 wrap는 동일한 instruct를 실행하는 Thread끼리 묶고, Core는 SM(Streaming multiprocessor)이라는 단위로 묶어서 warp : SM을 N:M으로 할당합니다. 이 때 SM의 Core 수와 Wrap 내의 Thread 수는 일치합니다.
- SIMD : 하나의 명령어로 여러 데이터를 동시에 처리하는 병렬 처리 기법
GPGPU, CUDA
- GPU는 그래픽 작업을 위해 나타난 만큼, 일반 데이터에도 적용하기 위해선 일반 데이터를 GPU가 처리할 수 있는 행렬 곱의 형태로 바꾸어 줄 필요가 있습니다.
- GPGPU(General Purpose GPU)는 일반 데이터를 GPU가 처리할 수 있는 데이터의 형태로 바꾸어주는 기술로, 이를 통해 그래픽 연산에만 사용되었던 GPU를 머신 러닝, 데이터 분석 등에서 GPU를 사용할 수 있게 됩니다.
- 대표적으로 NVIDIA의 CUDA 라이브러리가 이를 구현하였으며, CUDA 라이브러리는 C++ 기반의 라이브러리로 NVIDIA GPU가 GPGPU를 위한 기능을 제공해줄 뿐만 아니라 GPU의 효율적인 병렬 처리 아키텍쳐를 위한 알고리즘과 프로그래밍 모델을 포함합니다.
CUDA Programming Model
- CUDA 프로그래밍 모델은 어플리케이션과 GPU 하드웨어 사이의 어떠한 관계가 있는지 보여주는 GPU 아키텍처의 추상화를 제공한다고 합니다.
- CUDA 프로그래밍 모델에서는 host와 device를 정의하는데, host는 CPU, host memory는 System Memory(RAM), device는 GPU, device memory는 VRAM을 의미합니다.
- CUDA 프로그램을 실행하기 위해선 아래의 과정을 수행합니다.
- Host Memory의 Input Data를 Device Memory로 전달
- GPU 프로그램을 load하고 실행하며, 이 때 warp를 CUDA Block이라고 하며, CUDA Block은 하나의 SM에 할당되어 실행됩니다.
- GPU 프로그램의 Output을 Host Memory로 전달
- CUDA 라이브러리를 사용해 실제 GPU 프로그램을 만드는 과정은 링크에서 확인하실 수 있습니다.

- 위 그림은 Nvidia GPU를 사용할 때 CUDA 아키텍쳐 모델입니다.
- 위 그림에 따른 CUDA 소프트웨어의 정의는 아래와 같습니다.
- CUDA Toolkit(libraries, runtime and tools) : CUDA 애플리케이션을 빌드하는 데 사용되는 사용자 모드 SDK
- CUDA Driver : CUDA 응용 프로그램을 실행하는 데 사용되는 사용자 모드 드라이버 구성 요소(e.g. libcuda.so on Linux systems)
- NVIDIA GPU device driver: NVIDIA GPU용 커널 모드 드라이버 구성 요소
- CUDA는 이렇게 일반 데이터를 GPU가 처리할 수 있는 형태의 데이터로 바꾸어 줄 뿐만 아니라, cuDNN, cuBLAS와 같이 특정 작업에 GPU를 가속화하는 라이브러리 또한 제공합니다.
- 또 CUDA C, C++ 코드는 nvcc라는 특수 컴파일러에 의해 컴파일 되며, 호스트 코드와 디바이스 코드를 분리하여 처리합니다.
GPU Driver, CUDA, cuDNN의 버전 관계
- 딥러닝 개발자들이 처음 GPU를 사용해서 환경을 구축할 때, 가장 어려워 하는 것 중 하나가 GPU Driver, CUDA, cuDNN, nvcc , pytorch 등의 버전 관리인데요, 어떻게 해야 오류 없이 잘 구동 시킬 수 있을까요?
- 먼저 GPU Driver, CUDA, cuDNN에 대한 설치는 여기서 잘 정리되어 있었습니다.
- Docker 환경에서 CUDA를 사용하기 위해선 Docker용 NVIDIA Container Toolkit을 설치해야 합니다. (공식 문서)
- nvidia-docker를 사용해 GPU를 사용하는 컨테이너는 호스트의 GPU Driver와 공유합니다.
내 GPU에 맞는 CUDA 버전 맞추기
- 먼저 내 GPU에 맞는 CUDA 버전을 아는 방법은 다음과 같습니다.
1. 링크에서 내 GPU와 OS 정보를 입력해 GPU Driver 설치
2. nvidia-smi 를 입력해 자신의 GPU가 지원하는 최대 CUDA Version 확인

3. 링크를 통해 내가 설치하고 싶은 pytorch 버전 체크 및 CUDA 버전 체크

4. 링크를 통해 선택한 pytorch의 버전이 필요로하는 python version을 체크
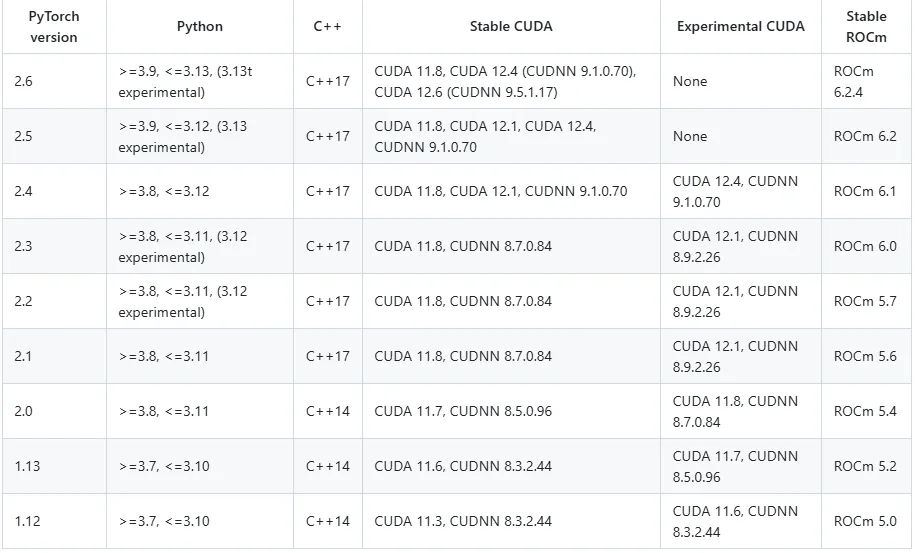
5. (Docker) nvidia/cuda 이미지의 위에서 설정한 버전과 맞는 BASE 이미지 선택

- 앞서 확인한 Nvidia-smi 를 통해 추천 받은 버전은 12.6이였지만, 12.6이하의 CUDA는 호환되는 경우가 많기 때문에 12.4를 설치했습니다. 만약 CUDA 버전이 GPU Driver에 비해 너무 낮다면 GPU Driver 버전을 낮추는 것을 고려해야 합니다.
6. 필요한 Python 및 pytorch 버전 설치
FROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu22.04
WORKDIR /app
COPY requirements.txt /app/requirements.txt
COPY model /app/model
COPY app.py /app/main.py
COPY epoch2 /app/epoch2
RUN apt-get update && apt-get install -y \
wget build-essential zlib1g-dev libssl-dev libncurses-dev libffi-dev \
libsqlite3-dev libreadline-dev libbz2-dev liblzma-dev
RUN wget https://www.python.org/ftp/python/3.12.0/Python-3.12.0.tgz \
&& tar -xvf Python-3.12.0.tgz \
&& cd Python-3.12.0 \
&& ./configure --enable-optimizations \
&& make -j$(nproc) \
&& make install \
&& ln -s /usr/local/bin/python3.12 /usr/bin/python3
RUN pip3 install --upgrade pip
RUN pip3 install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu124
RUN pip3 install -r requirements.txt
EXPOSE 8000
CMD ["uvicorn", "main:app"]
- 또는 pytorch 이미지를 활용해도 좋습니다.
nvidia/cuda docker Image의 base, runtime, devel 태그
- nvidia/cuda 이미지의 Document에 따르면 image는 base, runtime, devel 태그로 나뉘는데요, 각 역할은 다음과 같습니다.
- base : CUDA 런타임 만을 포함한 기본적인 이미지로, CUDA 애플리케이션을 배포하는 데 필요한 최소한의 구성 요소, CUDA 런타임(cudart)을 포함합니다.
- runtime : base 이미지를 확장하여 CUDA 수학 라이브러리 및 NCCL을 포함합니다. cuDNN도 포함된 runtime 이미지를 사용할 수 있습니다.
- devel : runtime 이미지를 확장하여 컴파일러 도구 체인, 디버깅 도구, 헤더 파일, 정적 라이브러리를 추가로 포함하며, CUDA 어플리케이션을 직접 개발하여 빌드할 때 사용합니다.
cuda 라이브러리에는 어떤게 있을까?
nvidia cuda library sample github에 따르면, CUDA 라이브러리에는 아래의 종류가 있다고 합니다.
- libcudart.so: CUDA 런타임 라이브러리
- libcublas.so: cuBLAS (Basic Linear Algebra Subprograms) 라이브러리
- libcufft.so: cuFFT (Fast Fourier Transform) 라이브러리
- libcurand.so: cuRAND (Random Number Generation) 라이브러리
- libcusolver.so: cuSOLVER (Dense and Sparse Solvers) 라이브러리
- libcusparse.so: cuSPARSE (Sparse Matrix Operations) 라이브러리
- libnpp.so: NPP (NVIDIA Performance Primitives) 라이브러리
- libnvjpeg.so: nvJPEG (JPEG Encode/Decode) 라이브러리
참고
- https://aws.amazon.com/ko/compare/the-difference-between-gpus-cpus/
- https://hongcoding.tistory.com/139
- https://xoft.tistory.com/75
- https://taegyunwoo.github.io/comput-struct/ComputerStructure_InstructionSet
- https://acecloud.ai/resources/blog/why-gpu-memory-matters-more-than-you-think/
- https://ko.wikipedia.org/wiki/GPGPU
- https://webzero.tistory.com/3686
- https://blog.hyelie.com/entry/이종병렬컴퓨팅-GPU-architectures-SIMT와-SIMD
- https://www.youtube.com/watch?v=ZdITviTD3VM&list=LL
- https://junstar92.tistory.com/246
- https://docs.nvidia.com/datacenter/tesla/drivers/index.html
- https://xoft.tistory.com/85
반응형