반응형
안녕하세요, 이번에 준비한 글은 Transformer 아키텍처가 처음 시작된 Attention is All You Need 논문 번역 + 정리본입니다. 복잡한 수식은 제외하고 전체적인 흐름을 파악하는데 집중하였습니다. 논문 본문의 링크는 다음과 같습니다.
https://arxiv.org/pdf/1706.03762
개요
- 기존의 시퀀스 변환 모델은 RNN 기반의 Encoder, Decoder로 구성되며, 그 중 Attention 매커니즘을 사용하는 구조가 가장 성능이 뛰어나다.
- 하지만 RNN 기반의 시퀀스 변환 모델은 두가지의 문제가 있음.
- 새 은닉 상태 생성 시 이전 은닉상태를 사용하는 순환적 특성으로 병렬화의 어려움
- Context Vector의 고정된 크기로 인해 긴 길이의 문장을 처리하는데 성능이 떨어짐
- 해당 논문에선 RNN이나 CNN을 사용하지 않고, 어텐션 매커니즘만을 적용한 새로운 아키텍처인 Transformer 아키텍처를 제안
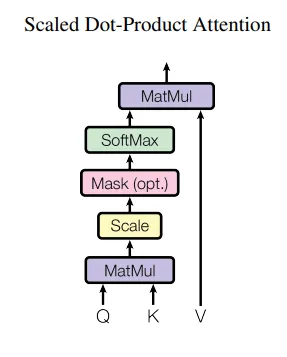
Scaled Dot-Product Attention
- Self-Attention은 문장 내부에서 각 단어가 다른 단어와 얼마나 관련이 있는지를 계산하는 방식
- 어텐션(Attention) 함수는 Query, Key, Value를 입력으로 받아 출력을 생성하는 함수로, 도식화 및 코드는 아래와 같음.
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super(SelfAttention, self).__init__()
self.embed_dim = embed_dim
# Q, K, V를 생성하는 Linear 레이어
self.W_Q = nn.Linear(embed_dim, embed_dim, bias=False)
self.W_K = nn.Linear(embed_dim, embed_dim, bias=False)
self.W_V = nn.Linear(embed_dim, embed_dim, bias=False)
def forward(self, X):
"""
X: (batch_size, seq_len, embed_dim)
"""
# Q, K, V 생성
Q = self.W_Q(X) # (batch, seq_len, embed_dim)
K = self.W_K(X) # (batch, seq_len, embed_dim)
V = self.W_V(X) # (batch, seq_len, embed_dim)
# Q ⊙ K^T (내적)
scores = torch.bmm(Q, K.transpose(1, 2)) # (batch, seq_len, seq_len)
# Softmax 적용하여 Attention Weights 계산
attention_weights = F.softmax(scores / (self.embed_dim ** 0.5), dim=-1) # (batch, seq_len, seq_len)
# Attention Weights ⊙ V (Context Vector 계산)
context_vector = torch.bmm(attention_weights, V) # (batch, seq_len, embed_dim)
return context_vector, attention_weights- 이 때 입력 문장 X에 대해 생성되는 Q, K, V의 각각의 의미는 다음과 같다.
- Q : 내가 찾으려는 정보
- K : 각 단어가 가진 특징
- V : 실제 정보를 담고 있는 값
- Q와 K에 내적을 수행하고, softmax를 거치면 각 단어가 다른 단어와 얼마나 연관이 있는지 알 수 있는 attention_weight를 구할 수 있으며, 그 예시는 아래와 같다.
Attention_Weights = [
[0.1602, 0.2875, 0.2333, 0.3190], # "I"
[0.1615, 0.2854, 0.3226, 0.2305], # "am"
[0.1614, 0.3247, 0.2296, 0.2843], # "a"
[0.3251, 0.2838, 0.2295, 0.1615] # "student"
]
- 여기서 I는 student, am은 a, a는 am, student는 i가 가장 연관이 크다고 판단하였다.
- 여기에 V를 곱함으로써 가중합(weighted sum)하여 최종 출력인 Attention 값을 얻을 수 있다.

Multi-Head Attention
- 기존의 어텐션 메커니즘은 single-head attention 을 수행하지만, 이를 확장한 Multi-Head Attention을 사용하면 더욱 풍부한 표현이 가능함.
- 멀티-헤드 어텐션은 다양한 위치에서, 서로 다른 특성에 집중할 수 있어 더욱 정확하고 풍부한 학습이 가능하다.

[ 기존 Self-Attention ]
입력 X ───▶ (Q, K, V 생성) ───▶ Attention 연산 ───▶ 최종 출력
[ Multi-Head Self-Attention ]
입력 X
├──▶ Head1: (Q1, K1, V1 생성) ───▶ Attention ───┐
├──▶ Head2: (Q2, K2, V2 생성) ───▶ Attention ───┤
├──▶ Head3: (Q3, K3, V3 생성) ───▶ Attention ───┤
└──▶ Head4: (Q4, K4, V4 생성) ───▶ Attention ───┘
⬇
(Concat) 최종 출력
전체적인 동작 원리는 아래와 같고, 코드는 아래와 같다. Multi-Head Attention에서 Qn, Kn, Vn은 hidden_dim 크기의 Q, K, V를 n_heads * head_dim으로 쪼개어 생성된다. 그 후 각 독립적인 Attention_weight 계산을 수행하고, 최종적으로 Concat 연산으로 합친다.
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hidden_dim, n_heads, dropout_ratio, device):
super().__init__()
assert hidden_dim % n_heads == 0
self.hidden_dim = hidden_dim # 임베딩 차원
self.n_heads = n_heads # 헤드(head)의 개수: 서로 다른 어텐션(attention) 컨셉의 수
self.head_dim = hidden_dim // n_heads # 각 헤드(head)에서의 임베딩 차원
self.fc_q = nn.Linear(hidden_dim, hidden_dim) # Query 값에 적용될 FC 레이어
self.fc_k = nn.Linear(hidden_dim, hidden_dim) # Key 값에 적용될 FC 레이어
self.fc_v = nn.Linear(hidden_dim, hidden_dim) # Value 값에 적용될 FC 레이어
self.fc_o = nn.Linear(hidden_dim, hidden_dim)
self.dropout = nn.Dropout(dropout_ratio)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask = None):
batch_size = query.shape[0]
# query: [batch_size, query_len, hidden_dim]
# key: [batch_size, key_len, hidden_dim]
# value: [batch_size, value_len, hidden_dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
# Q: [batch_size, query_len, hidden_dim]
# K: [batch_size, key_len, hidden_dim]
# V: [batch_size, value_len, hidden_dim]
# hidden_dim → n_heads X head_dim 형태로 변형
# n_heads(h)개의 서로 다른 어텐션(attention) 컨셉을 학습하도록 유도
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# Q: [batch_size, n_heads, query_len, head_dim]
# K: [batch_size, n_heads, key_len, head_dim]
# V: [batch_size, n_heads, value_len, head_dim]
# Attention Score 계산
score = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# Score: [batch_size, n_heads, query_len, key_len]
# 어텐션(attention) 스코어 계산: 각 단어에 대한 확률 값
attention_weights = torch.softmax(energy, dim=-1)
# attention: [batch_size, n_heads, query_len, key_len]
# 여기에서 Scaled Dot-Product Attention을 계산
context_vector = torch.matmul(self.dropout(attention_weights), V)
# context_vector: [batch_size, n_heads, query_len, head_dim]
# 계산한 Context_Vector를 다시 합침(Concat)
context_vector = context_vector.permute(0, 2, 1, 3).contiguous().view(batch_size, -1, self.hidden_dim)
# context_vector : [batch_size, query_len, hidden_dim]
x = self.fc_o(context_vector)
# x: [batch_size, query_len, hidden_dim]
return x, attention_weights
Transformer에서의 Attention 활용
- Transformer에서는 이러한 Multi-Head Attention을 3가지 방식으로 사용한다.
- Encoder-Decoder Attention
- 쿼리(Query)는 현재 디코더의 입력, 키(Key)와 값(Value)은 인코더의 출력에서 가져옴
- Decoder가 이전에 생성했던 단어와 입력 문장 전체를 고려하여 다음 단어를 예측하는데 사용
- Encoder Self-Attention
- 쿼리(Query), 키(Key), 값(Value)이 모두 **이전 인코더 레이어의 출력(첫번째 층은 입력 임베딩)**에서 가져온다.(즉, Q,K,V 모두 인코더에서 생성)
- 입력 문장의 각 단어들 사이의 관계를 파악하기 위해 사용
- Decoder Self-Attention
- 쿼리(Query), 키(Key), 값(Value)이 모두 디코더 레이어의 출력
- 이전 시점까지의 단어들과의 관계를 학습하여 문맥을 이해하는 데 도움을 줌
- 미래 단어를 보지 못하도록 Masking을 적용하여, 이전까지 생성된 단어들만 참고할 수 있도록 함
Position-wise Feed-Forward Networks
- 두 개의 선형 변환과 그 사이의 ReLU 활성화 함수로 구성된다.
- 이 네트워크는 Encoder Layer와 Decoder Layer당 하나의 독립적인 Feed-Forward Network를 가짐

Positional Encoding
- Transformer 모델은 순환이나 합성곱을 포함하지 않기 때문에, 시퀀스 내에서 토큰의 순서(order)를 활용할 수 있도록 별도의 위치 정보를 추가해야 한다
- 이를 위해, "포지셔널 인코딩(Positional Encoding)"을 인코더와 디코더 스택의 입력 임베딩에 추가한다.
- 포지셔널 인코딩의 차원은 입력 임베딩의 차원과 같아서 더할 수 있도록 설계됨.

Encoder
- Transformer의 인코더는 총 N개의 동일한 레이어로 구성되며, 각 레이어는 아래의 서브 레이어를 갖는다.
- Encoder Self-Attention를 기반으로 입력 시퀀스 내에서 각 토큰이 다른 모든 토큰과 관계를 학습할 수 있도록 함.
- Feed-Forward Network를 기반으로 비선형 변환(유연한 표현)
- 각 서브 레이어에는 Residual Connection과 Layer Normalization이 추가되어, 각 서브 레이어의 출력은 다음과 같이 계산된다.

Decoder
Transformer의 디코더는 총 N개의 동일한 레이어로 구성되며, 각 레이어는 아래의 세 가지 서브 레이어를 포함한다.
- Decoder Self-Attention을 통해 디코더가 지금까지 생성한 단어들 간의 관계를 학습한다.
- Encoder-Decoder Attention을 통해 입력 전체 문장과 디코더의 현재 상태 간 관계를 학습한다.
- Feed-Forward Network를 활용하여 비선형 변환을 수행하며, 보다 유연한 표현 학습을 가능하게 한다.
또한, 디코더에서도 각 서브 레이어에 잔차 연결(Residual Connection)과 Layer Normalization이 적용된다.

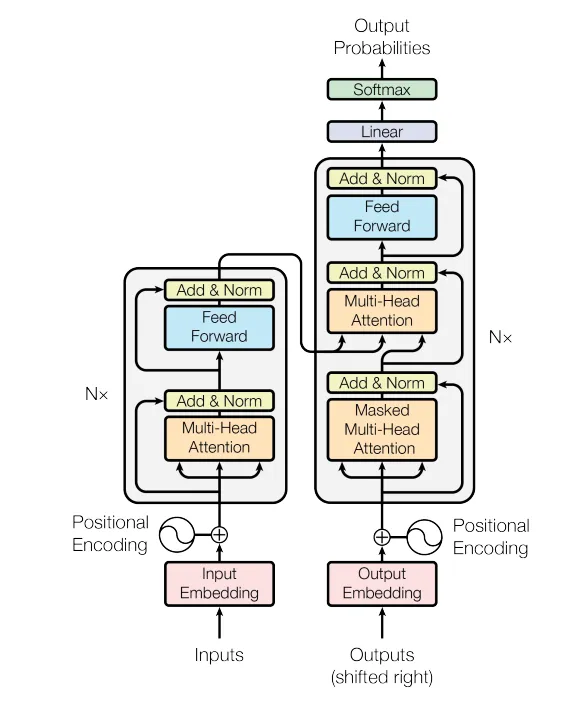
전체 아키텍처
- 이를 이용한 전체 아키텍처는 다음과 같다.
반응형

