반응형
이번에는 대표적인 LLM Serving Framework인 vLLM의 기반 논문에 대해 리뷰를 해보겠습니다.
논문 원본 링크와 vLLM의 github 링크는 아래와 같습니다.
https://arxiv.org/pdf/2309.06180
https://github.com/vllm-project/vllm
개요
- KV 캐시는 LLM의 추론 속도를 올려주는 역할을 수행함.
- 하지만, vLLM 이전의 LLM 추론 프레임 워크는 메모리 관리 정책이 부족해 메모리 낭비가 심했음.
- PagedAttention과 이를 적용한 vLLM은 2가지의 핵심 키워드로 LLM 추론 시에 메모리를 최적화 시킴
- OS의 가상 메모리 및 페이징 기법 적용
- 메모리 공유
이전 LLM 추론 프레임 워크의 문제점
- 이전 LLM 추론 프레임 워크(논문에서는 Orca와 비교)는 아래의 문제가 발생
- 내부 단편화 문제
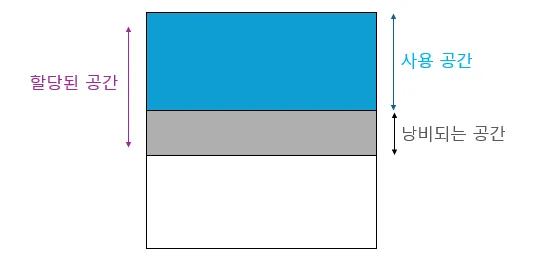
- 이전 LLM 추론 프레임 워크는 KV 캐시를 연속된 공간에 저장하기 위해, 각 요청의 최대 길이에 맞는 크기의 KV 캐시 공간을 할당한다. 하지만 KV가 최대 공간을 모두 활용하지 않으면 공간이 낭비된다.
2. 외부 단편화 문제
- 메모리를 할당-해제 하다보면 GPU 메모리의 공간이 비연속적으로 남게 되어 큰 메모리를 연속적으로 할당할 수 없는 문제가 발생할 수 있다.

3. 메모리 공유 문제
- LLM 추론 시 Parallel Sampling이나 Beam Search같은 하나의 요청에 대해 여러개의 출력을 동시에 생성하는 디코딩 알고리즘의 경우, 이 시퀀스가 부분적으로 K,V 값을 공유할 수 있음에도 그렇게 하지 않음.

Background
Virtual Memory & Paging
- 위 3가지 문제를 해결하기 위해 vLLM은 OS의 가상 메모리와 페이징 기법을 사용한다.
- vLLM의 가상 메모리와 페이징 기법을 이해하기 전에, OS는 어떻게 메모리 단편화 문제를 해결하는지 간단하게 확인해보자.
가상 메모리
- 프로세스마다 분리된 메모리 공간을 제공하는 것
- 프로세스의 가상 메모리 공간을 고정된 크기의 Page로 쪼개어 관리
- 프로세스는 가상 메모리만을 참조하고, 가상 메모리의 Page는 연속된 것 처럼 보이지만 실제로는 그렇지 않을 수 있음.
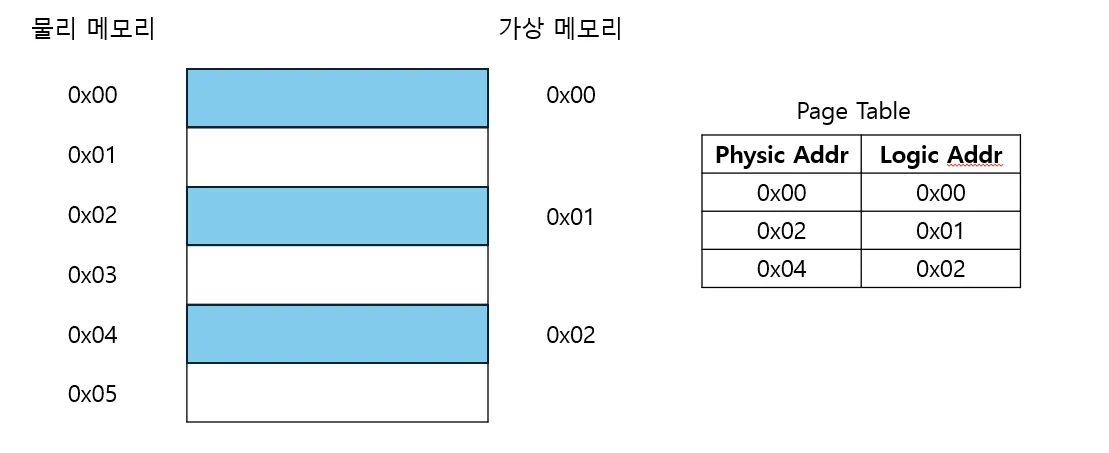
페이징
- 가상 메모리를 사용함으로써 디스크의 일부를 메모리처럼 사용할 수 있음
- 프로세스가 사용할 페이지가 메모리에 없으면(즉, 디스크에 있다면) 디스크에서 페이지를 불러와서 남는 프레임에 페이지를 할당(Paging)
Auto Regressive Model & KV Cache
- 다음으로는 Auto Regressive Model이 토큰을 출력하는 방식과, 이때 KV 캐시가 어떻게 사용되는지 간단히 살펴보자.
- Auto Regressive 모델은 크게 두가지의 단계로 나누어져 출력을 생성한다.
- Prefill Phase
- 사용자의 입력을 이해하는 단계
- 이때 사용자의 입력(예 : “오늘 날씨는 어때?”)이 들어왔을 때, 이에 대한 KV 값을 계산하고, 첫번째 출력 토큰을 생성한다.
- Decoding Phase
- 1단계에서 첫번째 토큰을 계산한 후, 새로운 토큰을 순차적으로 생성한다.
- 이때 마지막 토큰을 Q로, 이전 모든 토큰을 K,V 로 사용해 attention score를 사용한다.
- <eos> 토큰이 나올때 까지 반복된다.
- 1단계에서 첫번째 토큰을 계산한 후, 새로운 토큰을 순차적으로 생성한다.
- Decoding 단계에서 Q값은 매번 새로운(각 단계의 마지막)토큰이 들어오기 때문에 미리 계산할 수 없지만, K와 V는 이전에 들어온 모든 토큰을 사용하기 때문에 전 단계에서 이미 계산한 값이다. 따라서 K V값을 캐싱함으로서 K와 V를 다시 구하는 횟수를 줄일수 있고, 이것이 KV Cache이다.
Paged Attention & vLLM
- 이제 PagedAttention을 이해하기 위한 사전 지식은 알았으니, Paged Attention의 개념에 대해 살펴보자.
- vLLM은 K와 V를 블록으로 나누어 연속되지 않은 메모리에 관리한다.

- 이때 블록은 n개의 토큰의 K값 또는 V 값으로 이루어진다.
- 이렇게 블록 단위로 나누어진 K블록과 V블록을 기반으로, Paged Attention은 블록 단위의 Attention을 수행한다.


- 여기서 Aij는 i번째 쿼리와 j번째 블록을 어텐션 + sofmax한 Attention_Weight이다.
- 이제 VjAij를 곱해 모두 더한 값을 i번째 쿼리에 대한 전체 어텐션 값으로 사용할 수 있다.

KV Cache Manager
- 이렇게 비연속적인 메모리 내에서 블록 단위의 연산이 가능하려면, 각 블록이 실제 GPU 어느 위치에 있는지 알아야 한다.
- vLLM의 Cache Manager는 논리적 KV 블록과 물리적 KV 블록 간의 매핑을 수행하는 Block Table이 있기 때문에 논리적으로는 KV블록이 연속된 것처럼 사용될 수 있다.
- 이러한 구조 덕분에 vLLM은 미리 정해진 최대 길이의 메모리를 사전에 할당할 필요 없이, 필요에 따라 동적으로 KV캐시 메모리를 할당할 수 있다.
예시

- 이번에는 위 그림을 바탕으로 vLLM이 단일 입력 프롬프트의 디코딩 과정에서 PagedAttention을 어떻게 수행하고 메모리를 관리하는지 알아보자.
- 위 단계에서 블록당 4개의 토큰을 저장한다고 가정한다.
- Prefill 단계
- 입력은 “Four Score And Seven Years ago our”이라고 가정했을때, 토큰은 7개로, Prefill 단계에서 총 2개의 블록을 할당받아 8개의 공간을 할당 받는다.(1개의 공간이 남음)
- Decoding 단계
- 새로운 토큰이 생성되면서 새 토큰의 KV 값을 먼저 prefill 단계의 남는 1개의 공간에 저장하고, 그 후 새 블록을 할당받아 새로운 KV 값을 계속 저장한다.
- 결론적으로 KV를 블록 단위로 관리함으로써, 외부 단편화 문제를 완전히 해결하고 내부 단편화 문제를 많이 완화할 수 있다.
스케줄링 및 선점
- vLLM이 블록 단위 KV 캐시 관리를 적용했을 때, 해결해야 하는 문제가 두가지 더 있다.
- GPU 공간이 모자랄 때 어떤 블록을 삭제(evict)할 것인가?
- 삭제된 블록을 어떻게 다시 복구(recover)할 것인가?
블록 삭제 정책
- 일반적으로 삭제 정책은 가장 오랫동안 참조되지 않을 블록을 예측하고 삭제한다.
- 그러나 vLLM은 시퀀스의 모든 블록이 함께 접근되므로, 전부 삭제 또는 전부 삭제하지 않는 정책인 all-or-nothing 정책을 적용한다.
- 하나의 요청에 다수의 출력 시퀀스를 생성하는 경우에는 sequence group 스케줄링을 적용한다.
- 시퀀스 그룹 내의 시퀀스는 메모리를 공유할 수 있으므로, 시퀀스 그룹 단위로 함께 선점되거나 스케줄링 된다.
블록 복구 정책
- 블록을 삭제한 후 다시 복구하는 방법으로 두가지의 기법이 적용된다.
- Swapping
- OS와 마찬가지로 삭제된 페이지를 Swap 공간에 저장하는 방식
- OS는 Swap공간이 디스크지만, vLLM은 CPU 메모리에 복사한다.
- vLLM이 GPU 메모리에 물리적 블록 공간이 모잘라지면, 특정 시퀀스를 선택해 KV 캐시를 CPU 메모리로 전송하고 GPU 메모리에는 블록을 삭제한다.
- 그 후 선점된 시퀀스가 처리완료될 때까지 새 요청을 받지 않다가, 해당 시퀀스 처리가 완료되면 삭제된 시퀀스의 블록을 다시 GPU로 복구하여 처리한다.
- 이때 CPU RAM에 저장된 블록의 개수는 GPU RAM의 물리적 블록의 갯수를 초과하지 않도록 설계되어 있다.
- OS와 마찬가지로 삭제된 페이지를 Swap 공간에 저장하는 방식
- Recomputation(재계산)
- 삭제된 시퀀스의 KV 캐시를 다시 계산하는 방식
- CPU - GPU 메모리 사이의 대역폭, GPU의 연산 속도에 따라 Swapping보다 재계산이 빠를 수 있다.
메모리 공유
- 이제 vLLM에서 메모리 공유를 어떻게 하는지 알아보자.
- 많은 LLM 어플리케이션은 출력의 질을 높이기 위해서 하나의 입력 프롬프트에서 여러개의 출력 시퀀스를 동시에 생성하는 방식을 활용하며, 본 논문에서는 Parallel Sampling과 Beam Search, Shared Prefix에 대해 다룬다.
Parallel Sampling
- 하나의 입력에 대해 여러개의 출력을 생성하고, 사용자가 이 중 가장 마음에 드는 출력을 선택하는 방법
- 이 때 여러개의 출력을 생성할 때 입력 프롬프트의 KV 값은 공유될 수 있다.
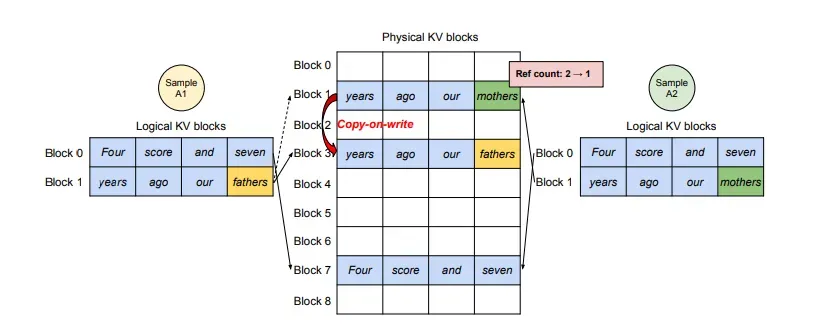
- 위 그림에서 입력 프롬프트로 “Four Score And Seven Years ago our”가 들어왔을때, 물리블록 1번과 7번은 공유된다.
- 각 물리 블록은 reference count를 갖고 있는데, Decoding 단계에서 Sample A1번이 Block 1의 빈 공간에 새로운 KV 값을 저장하려고 한다고 가정해보자.
- 이 때 물리 블록 1번은 reference count가 1이상(2) 이기 때문에, Block 1에 바로 쓰지 않고, 새로운 물리 블록을 할당받아 Block 1의 값을 그대로 복사하고, Sample A1은 Block 1이 아닌 새로운 블록을 할당 받는다.
- 이 방식을 CoW(Copy-On-Write) 방식이라고 한다.
- 이렇게 함으로써 여러개의 출력(샘플)은 마지막 블록을 제외한 모든 입력 단계의 KV 캐시를 공유하여 사용할 수 있다.
Beam Search
- Beam Search는 beam width를 사용하여, 각 디코딩 단계에서 가장 가능성 높은 k개의 후보 시퀀스를 유지하는 방법이다.
- 이렇게 빔 서치는 초기 프롬프트 블록 + 디코딩 과정에서 생성되는 다른 블록도 후보 시퀀스 간에 공유될 수 있다.(그림 참조)
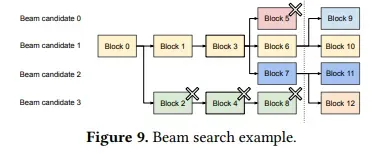
- 위 예제에서, 모든 빔 후보는 초기 프롬프트 블록(블록 0)을 공유한다
- 그 후 후보 3은 두 번째 블록부터 다른 후보들과 경로가 다르게 변형된다.
- 후보 0, 1, 2은 4번째 블록부터 분기된다.
- 빔서치 이후, 후보 0과 3은 상위 후보가 아니라 제외된다.(이때 Block 0. 2,4,8)이 메모리 해제
Shared Prefix
- 프롬프트 엔지니어링이 적용될 때, 입력 시퀀스마다 동일한 prefix가 들어가게 된다.
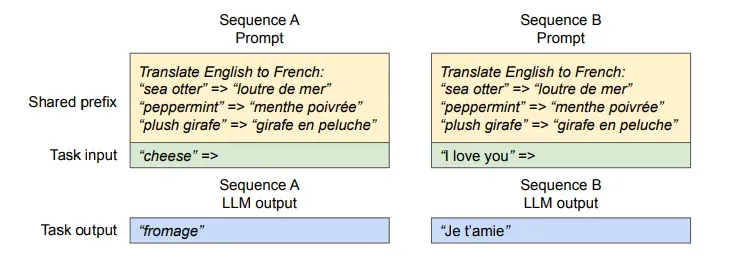
- vLLM에서는 아래의 방식으로 prefix 공유를 진행한다.
- prefix의 KV캐시를 미리 계산 및 저장
- KV Cache Manager은 prefix를 저장할 블록을 미리 예약
- 사용자의 입력 프롬프트가 공유 프리픽스를 포함할 경우
- 해당 프롬프트의 논리 블록을 미리 캐싱된 물리적 블록에 매핑
- 마지막 블록은 위에서 언급한 CoW 방식으로 처리
- 프롬프트 단계의 연산 최적화
- 프롬프트 단계에서 연산은 prefix는 캐싱, 나머지만 직접 계산할 수 있다.
- prefix의 KV캐시를 미리 계산 및 저장
분산 실행(Distributed Execution)
- 모델의 크기가 커서 모델을 여러 GPU에 나누는 방식으로 실행해야 한다. 이를 위해서는 분산 메모리를 효율적으로 처리하는 메모리 관리자가 필요하다.
- vLLM은 트랜스포머 모델에서 사용되는 Megatron-LM 스타일의 tensor model parallelism 전략을 지원해 분산 환경에서도 효율적으로 동작한다.
- 분산 실행시 vLLM은 연산을 수행하는 GPU 워커, 중앙화된 1개의 스케줄러를 가진다.
분산 실행 단계
- 분산 실행 단계를 간단하게 요약하면 다음과 같다.
- 스케줄러는 배치에 포함된 각 입력 토큰 ID 및 블록 테이블을 준비한다.(인코딩 단계)
- 스케줄러는 이제 처리하는 메시지를 모든 GPU워커(SPMD 프로세스)에 브로드캐스트 한다.
- GPU워커는 1단계에서 준비된 입력 시퀀스의 KV값을 재사용하며 연산 수행
- 실행 중 GPU 워커끼리 all-reduce 연산을 통해 중간 결과를 동기화(이 떄 스케줄러의 개입 없이 워커가 독립적으로 수행)
- 이렇게 완료된 토큰을 스케줄러에 반환
Mixed Decoding Methods
- 앞서 언급한 디코딩 방식은 각기 다른 메모리 공간을 가지기 때문에 메모리 공유는 어렵지만, vLLM에서는 서로 다른 디코딩 방식의 요청을 동시에 처리할 수 있다.
- 기존 시스템은 서로 다른 디코딩 방식의 메모리 공유 패턴을 직접 처리해야해서 배치 효율이 저하된다.
- vLLM에서는 아래와 같은 방식으로 해결한다.
- 공통 매핑 레이어
- vLLM은 논리 블록 - 물리 불록의 매핑을 처리하는 공통 매핑 레이어(매핑 테이블)을 사용한다.
- LLM과 실행 커널은 각 시퀀스에 대해 물리 블록 ID 목록만 참조하므로, 시퀀스 간의 메모리 공유 패턴을 직접 처리할 필요가 없다.
- 디코딩 방식간 메모리 공유 추상화
- 병렬 샘플링, 빔 서치, 프리픽스 공유 등에서 발생하는 복잡한 메모리 공유 패턴이 공통 매핑 레이어에서 처리된다. 따라서 메모리 접근만 하는 LLM의 입장에서는 메모리 접근이 일관되게 유지된다.
- 공통 매핑 레이어
- 결국 메모리 관리의 핵심은 공통 매핑 레이어
커널 수준 최적화
- PagedAttention은 기존 시스템에서 지원되지 않는 메모리 접근 패턴을 사용하므로 이를 최적화 하기위한 여러 GPU 커널을 새로 개발하였다. 아래는 개발된 최적화 기법에 대한 소개이다.
- 병합된 재구성 및 블록 쓰기(Fused Reshape and Block Write)
- 각 Transformer 레이어에서 새로 생성된 KV 캐시는 다음의 과정을 거친다.
- 블록 단위 분할
- 블록 읽기에 최적화된 레이아웃으로 재구성
- 블록 테이블에 저장
- 이러한 과정을 단일 커널로 병합하여 커널 호출을 최소화 함.
- 각 Transformer 레이어에서 새로 생성된 KV 캐시는 다음의 과정을 거친다.
- 병합된 블록 읽기 및 어텐션(Fusing Block Read and Attention)
- 기존 FasterTransforemr에서 사용된 어텐션 커널을 수정하여 다음이 수행되도록 함.
- 블록 테이블에 따라 KV 캐시를 읽기
- 읽은 값으로 즉시 어텐션 연산 수행
- 기존 FasterTransforemr에서 사용된 어텐션 커널을 수정하여 다음이 수행되도록 함.
- 병합된 블록 복사(Fused Block Copy)
- CoW에서 발생하는 연속되지 않은 블록에서 수행될 수 있음
- 이때 cudaMemcpyAsyn API는 작은 데이터 이동이 자주 발생해 성능 저하가 발생할 수 있음
- 이를 해결하기 위해 여러 블록의 복사 작업을 단일 커널로 병합해, 하나의 커널 실행으로 복사 작업을 병렬 처리
반응형
'ML > 논문' 카테고리의 다른 글
| [논문 리뷰] Orca: A Distributed Serving System forTransformer-Based Generative Models (1) | 2025.03.25 |
|---|---|
| [논문 리뷰]Attention is All You Need (0) | 2025.03.05 |

